
看穿機器學習(W-GAN模型)的黑箱
2017-03-01 by:CAE仿真在線 來源:互聯網
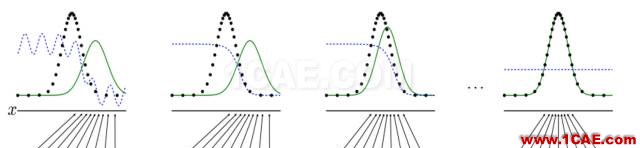
圖a. Principle of GAN.
這學期,老顧在講授一門研究生水平的數字幾何課程,目前講到了2016年和丘成桐先生、羅鋒教授共同完成的一個幾何定理【3】,這個工作給出了經典亞歷山大定理(Alexandrov Theorem)的構造性證明,也給出了最優傳輸理論(Optimal Mass Transportation)的一個幾何解釋。
這幾天,機器學習領域的Wasserstein GAN突然變得火熱,其中關鍵的概念可以完全用我們的理論來給出幾何解釋,這允許我們在一定程度上親眼“看穿”傳統機器學習中的“黑箱”。
下面是老顧下周一授課的講稿。
訓練模型 生成對抗網絡GAN (Generative Adversarial Networks)是一個“自相矛盾”的系統,就是以己之矛克以己之盾,在矛盾中發展,使得矛更加鋒利,盾更加強韌。這里的矛被稱為是判別器(Descriminator),這里的盾被稱為是生成器(Generator)。
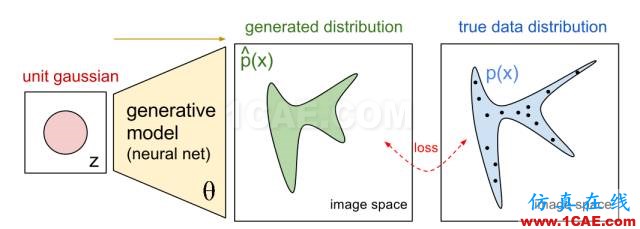
圖b. Generative Model.
生成器G一般是將一個隨機變量(例如高斯分布,或者均勻分布),通過參數化的概率生成模型(通常是用一個深度神經網來進行參數化),進行概率分布的逆變換采樣,從而得到一個生成的概率分布。判別器D也通常采用深度卷積神經網。
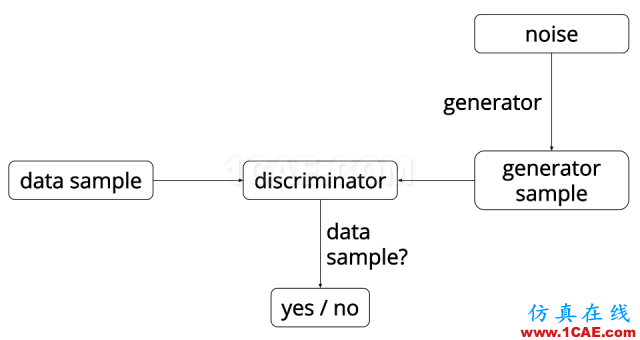
圖1. GAN的算法流程圖。
矛盾的交鋒過程如下:給定真實的數據,其內部的統計規律表示為概率分布

,我們的目的就是能夠找出

,我們希望
盡量接近
。為了區分真實概率分布
和生成概率分布

。
第一項不依賴于生成器G, 此式也可以定義GAN中的生成器的損失函數。
在訓練中,判別器D和生成器G交替學習,最終達到納什均衡(零和游戲),判別器無法區分真實樣本和生成樣本。
優點 GAN具有非常重要的優越性。當真實數據的概率分布不可計算的時候,傳統依賴于數據內在解釋的生成模型無法直接應用。但是GAN依然可以使用,這是因為GAN引入了內部對抗的訓練機制,能夠逼近一下難以計算的概率分布。更為重要的,Yann LeCun一直積極倡導GAN,因為GAN為無監督學習提供了一個強有力的算法框架,而無監督學習被廣泛認為是通往人工智能重要的一環。
缺點 原始GAN形式具有致命缺陷:判別器越好,生成器的梯度消失越嚴重。我們固定生成器G來優化判別器D。考察任意一個樣本


兩邊對


代入生成器損失函數,我們得到所謂的Jensen-Shannon散度(JS)

。
在這種情況下(判別器最優),如果

改進 本質上,JS散度給出了概率分布
為此,我們引入最優傳輸的幾何理論(Optimal Mass Transportation),這個理論可視化了W-GAN的關鍵概念,例如概率分布,概率生成模型(生成器),Wasserstein距離。更為重要的,這套理論中,所有的概念,原理都是透明的。例如,對于概率生成模型,理論上我們可以用最優傳輸的框架取代深度神經網絡來構造生成器,從而使得黑箱透明。
給定歐氏空間中的一個區域

,上面定義有兩個概率測度

和

,滿足

,
我們尋找一個區域到自身的同胚映射(diffeomorphism),

, 滿足兩個條件:保持測度和極小化傳輸代價。
保持測度 對于一切波萊爾集

,

換句話說映射T將概率分布
映射成了概率分布
,記成

。直觀上,自映射

,帶來體積元的變化,因此改變了概率分布。我們用
和
來表示概率密度函數,用


,

,
這被稱為是雅克比方程(Jacobian Equation)。
最優傳輸映射 自映射
的傳輸代價(Transportation Cost)定義為

在所有保持測度的自映射中,傳輸代價最小者被稱為是最優傳輸映射(Optimal Mass Transportation Map),亦即:

,
最優傳輸映射的傳輸代價被稱為是概率測度
和概率測度
之間的Wasserstein距離,記為

。
在這種情形下,Brenier證明存在一個凸函數

,其梯度映射

就是唯一的最優傳輸映射。這個凸函數被稱為是Brenier勢能函數(Brenier potential)。
由Jacobian方程,我們得到Brenier勢滿足蒙日-安培方程,梯度映射的雅克比矩陣是Brenier勢能函數的海森矩陣(Hessian Matrix),

。
蒙日-安培方程解的存在性、唯一性等價于經典的凸幾何中的亞歷山大定理(Alexandrov Theorem)。
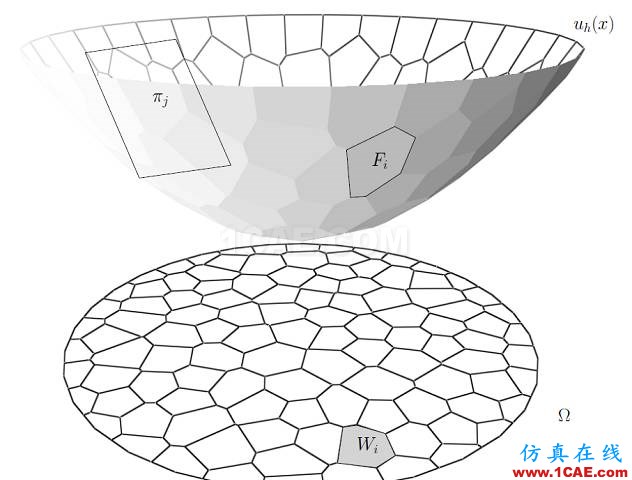
圖2. 亞歷山大定理。
亞歷山大定理 如圖2所示,給定平面凸區域

,考察一個開放的凸多面體

,選定一個面

,
的法向量記為

,
的投影和



凸多面體可以被

后面,我們可以看到,這個凸多面體就是Brenier勢能函數,其梯度映射將一個概率分布

映到另外一個概率分布

Wasserstein-GAN模型中,關鍵的概念包括概率分布(概率測度),概率測度間的最優傳輸映射(生成器),概率測度間的Wasserstein距離。下面,我們詳細解釋每個概念所對應的構造方法,和相應的幾何意義。
概率分布 GAN模型中有兩個至關重要的概率分布(probability measure),一個是真實數據的概率分布

,一個是生成數據的概率分布


圖3. 由保角變換(conformal mapping)誘導的圓盤上概率測度。
概率測度可以看成是一種推廣的面積(或者體積)。我們可以用幾何變換隨意構造一個概率測度。如圖3所示,我們用三維掃描儀獲取一張人臉曲面,那么人臉曲面上的面積就是一個概率測度。我們縮放變換人臉曲面,使得總曲面等于

我們可以將以上的描述嚴格化。人臉曲面記為

,其上具有黎曼度量

。平面圓盤記為

,平面坐標為

,平面的歐氏度量為

。保角映射記為

則

,這里面積變換率函數

給出了概率密度函數。

誘導了圓盤
上的一個概率測度

。

圖4. 兩個概率測度之間的最優傳輸映射。
最優傳輸映射 圓盤上本來有均勻分布


,則存在唯一的最優傳輸映射

。圖4顯示了這個映射

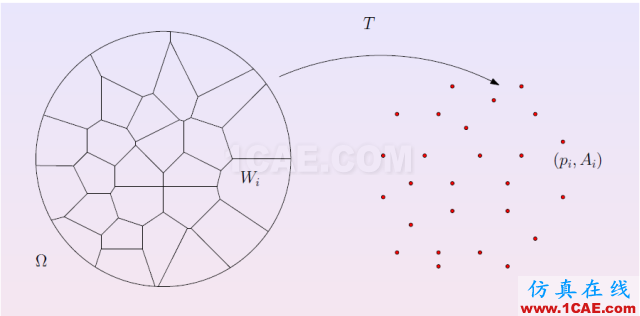
圖5. 離散最優傳輸。
離散最優傳輸映射 最優傳輸映射的數值計算非常幾何化,因此可以直接被可視化。我們將目標概率測度離散化,表示成一族離散點,

;每點被賦予一個狄拉克測度,

,滿足

。然后,我們求得單位圓盤的一個胞腔分解,

,每個胞腔

映到相應的目標點

,

。映射保持概率測度,胞腔的面積等于目標測度,

同時極小化傳輸代價,

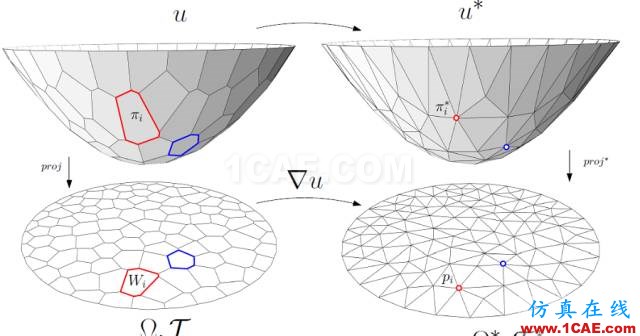
圖6. 離散Brenier勢能函數,離散最優傳輸映射。
離散Brenier勢能 離散最優傳輸映射是離散Brenier勢能函數的梯度映射。對于每一個目標離散點
,我們構造一個平面

,這里平面的截距

的圖(Graph),

。
圖6左側顯示了離散Briener勢能函數。凸多面體在平面上的投影構成了平面的胞腔分解,凸多面體的每個面

被映成了一個胞腔
;每個面
的梯度都是
,因此Brenier勢能函數的梯度映射就是

。
根據保測度性質,每個胞腔
的面積應該等于指定面積

。由此,我們調節平面的截距

離散Wasserstein距離 我們和丘成桐先生建立了變分法來求取平面的截距

。給定截距向量

,平面族為

,其上包絡構成的Briener勢能函數為

, 上包絡的投影生成了平面的胞腔分解

, 胞腔的面積記為

。我們定義的能量為,

這個能量在子空間


圖7給出了柱體體積的可視化,柱體體積

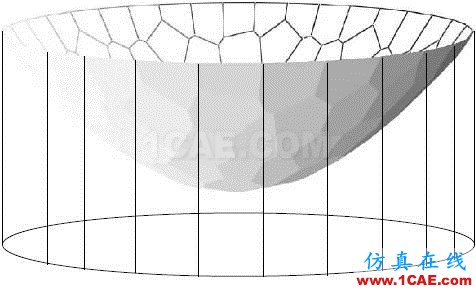
圖7. 離散Brenier勢能函數的圖截出的柱體體積
。
體積函數
,其圖



,函數的切線的斜率為y,則此切線的截距滿足

,
這被稱為是函數
的勒讓德變換。

以切線的斜率為參數,以切線的截距為函數值。
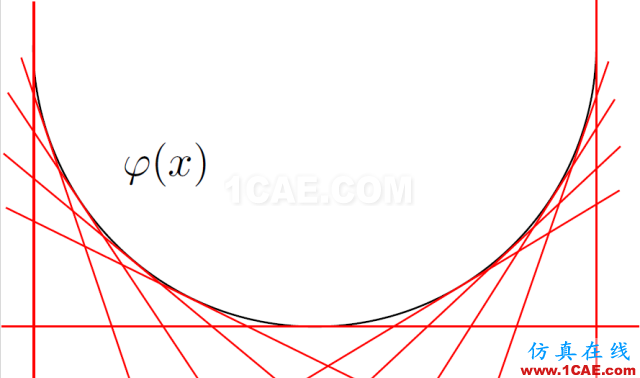
圖8.凸函數的圖像由其切線包絡而成,切線集合被表示成原函數的勒讓德對偶。
因為
的凸性,映射

是微分同胚,記為

。那么,原函數和勒讓德變換后的函數滿足關系:

,
這里c,d是常數。原函數和其勒讓德變換的直觀圖解由圖9給出。我們在xy-平面上畫出曲線
,曲線下面的面積是
,曲線上面的面積是勒讓德變換
。
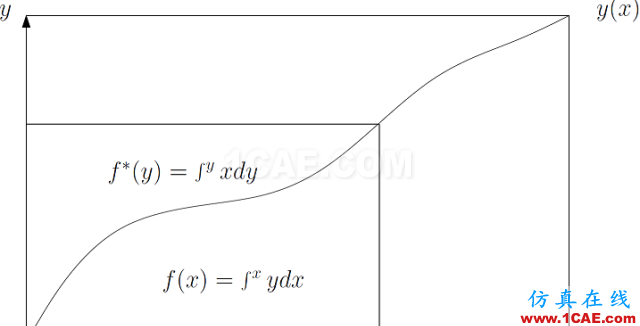
圖9. 圖解勒讓德變換。
勒讓德變換的幾何圖景對任意維都對。我們下面來考察體積函數
的勒讓德變換

。根據定義,

,
假如我們變動截距
,或者等價地變動胞腔面積

,考察兩個胞腔交界處

,

,
p本來屬于

,變化后屬于
,所有這種點的總面積為

。則為Wasserstein距離帶來的變化是:

因此,總的Wasserstein距離的變化是

。
由此我們看到Wasserstein距離等于

,
其非線性部分是柱體積的勒讓德變換。
通過以上討論,我們看到給定兩個概率分布

,則存在唯一的一個凸函數(Brenier 勢函數)
,其梯度映射

把一個概率分布

在Wasserstein-GAN模型中,通常生成器和判別器是用深度神經網絡來實現的。根據最優傳輸理論,我們可以用Briener勢函數來代替深度神經網絡這個黑箱,從而使得整個系統變得透明。在另一層面上,深度神經網絡本質上是在訓練概率分布間的傳輸映射,因此有可能隱含地在學習最優傳輸映射,或者等價地Brenier勢能函數。對這些問題的深入了解,將有助于我們看穿黑箱。

圖10. 基于二維最優傳輸映射計算的曲面保面積參數化(area preserving parameterization),蘇政宇作。

圖11. 基于三維最優傳輸映射計算的保體積參數化 (volume preserving parameterization),蘇科華作。
(在2016年,老顧撰寫了多篇有關最優傳輸映射的博文,非常欣慰地看到這些文章啟發了一些有心的學者,發表了SIGGRAPH論文,申請了NSF基金。感謝大家關注老顧談幾何,希望繼續給大家靈感。)
[1]Arjovsky, M. & Bottou, L.eon (2017) Towards Principled Methods for Training Generative Adversarial Networks
[2] Arjovsky, M., Soumith, C. & Bottou, L.eon (2017) Wasserstein GAN.
[3] Xianfeng Gu, Feng Luo, Jian Sun and Shing-Tung Yau, Variational Principles forMinkowski Type Problems, Discrete Optimal Transport, and Discrete Monge-Ampere
Equations, Vol. 20, No. 2, pp. 383-398, Asian Journal of Mathematics (AJM), April 2016.
相關標簽搜索:看穿機器學習(W-GAN模型)的黑箱 有限元技術培訓 有限元仿真理論研究 有限元基礎理論公式 能量守恒質量守恒動量守恒一致性方程 有限體積法 什么是有限元 有限元基礎知識 有限元軟件下載 有限元代做 Fluent、CFX流體分析 HFSS電磁分析 Ansys培訓




